

Rust is a relatively new systems programming language that started in 2009, and whose main claims to fame are its novel take on memory management and extremely loyal fanbase. Today we talk about my experience pivoting from 15+ years combined C++/Python/JavaScript knowledge to my new Rust language.
In my little experience, Rust is kind of like a weird bastardization of C++ and Python, but that’s probably a gross oversimplification. Rust retains certain properties from C/C++, (typed declarations, generics, macros) other aspects from Python, (multi-paradigm structure, closures, tuple unpacking, package management) and also introduces lots of new quirks that make it unique (ownership, results, traits).
Because of its lack of parallels to any other one language, Rust has a pretty steep learning curve. However, its new concepts intrigued me, so I decided to dive in headfirst. It started with re-implementing a few of my final exam questions from this past semester in Rust, then pivoted into writing this exceptionally long blog post on acclimating to the language.
The main point of this document is to help explain some of the more radically different fundamentals in Rust to developers familiar with C++ and/or Python, which coincidentally, makes up like 90% of all computer science students. It starts by talking primarily about memory, then pivots into other subjects such as Traits, Errors, and Closures. This document, in combination with the official documentation and books, should be enough to get any CS student started with Rust. I hope this document is an enjoyable read and let me know if you have any feedback by emailing me at me [at] azureagst [dot] dev!
1.) Everything is Immutable (By Default)
If you’ve ever worked on any remotely advanced project in C or C++, you should be familiar with how programs are structured in memory. For the uninitiated: when you compile a program in C/C++ and load it, the kernel will load your program into memory and split it up into 5 main parts: Text, Data, BSS, Stack, and Heap. Text stores the instructions for the program, Data and BSS store initialized and uninitialized global/static variables respectively, and the main sections of memory you’ll work in your program are the stack and the heap.
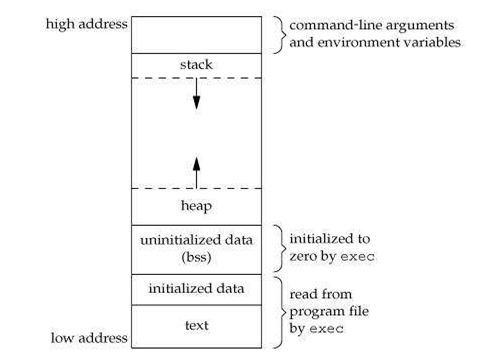
Both the stack and heap are able to store data that corresponds to variables, but the stack is— for all intents and purposes— ephemeral. Variables stored on the stack must have a known size upon compile (i.e. primitives, arrays with static sizes, etc.) and stack variables only exist as long as they are within scope.
For example: upon exiting a function, the kernel will free any memory it allocated for use during your function’s runtime and jump to the previous return address. So if you were to allocate a static character array within a function, do some work on that array, then try to return a reference to said array, the parent function will receive a bogus reference containing an address to a section in memory that was freed upon your function returning!
// For example: this would not work, and
// potentially lead to undefined behavior!
char* bad_return_string(void) {
char str[100];
memset(str, '\0', sizeof(str));
strcpy(str, "This is a string!\n");
return str;
}
That’s why for dynamically-sized or persistent variables, (i.e. structures, mutable strings, dynamic arrays, etc.) our data must be stored on the heap. The heap is a section of memory that the developer can use to persist values throughout the program’s lifetime. In C, you’d allocate memory on the heap using the malloc() family of functions (or the new keyword in C++) and refer to the data within memory via a pointer variable. Pointers are a static size, so it meets our static-size requirement for a stack variable. We can then use this pointer to refer to the string anywhere throughout the program’s lifetime, no matter the current scope. We’d also need to free the memory later in execution using free() or delete, but that’s a sidenote for now.
// This is a "good" function that returns a
// string on the heap. Note that we don't free
// here, and assume the programmer frees later.
char* good_return_string(void) {
char* str = malloc(100 * sizeof(char));
memset(str, '\0', sizeof(str));
strcpy(str, "This is a string!\n");
return str;
}
The issue with C/C++ here is that both snippets of code are able to compile. (That is, if you ignore a few warnings.) If you’re a lower-level developer working in higher-level development, like OS or kernel module projects, you might run into stack/heap issues pretty frequently. Rust aims to solve this problem by implementing a radical approach: declaring all variables immutable by default.
// This doesn't fly in Rust!
let x = 10;
x = 11;
Anything declared with let is immutable and allocated on the stack by default. Anything declared with let mut is mutable and allocated on the heap by default, unless it’s a data type that has a constant size like f32 or u64. This split approach means that issues, like our freed string reference, are no longer an issue. Declaring the stack immutable also helps prevent many common binary vulnerabilities like buffer overflows. Can’t overwrite the return address if the size of items on the stack can’t be changed!
This new line of thought takes a while to get used to, but handling variable storage this way has lots of perks to it.
2.) Ownership, Borrowing, and Memory Allocation
2.1) Ownership in a Single Block
Now, you may notice that in my earlier “good” string example, the memory we allocated was never freed in the snippet. This could lead to memory leaks later down the line, which could cause performance issues later in your program. This is a great introduction to C/C++’s Achilles heel: memory management.
C and C++ both give developers extremely granular control over memory. This is one of their main claims to fame. Because they let the developer explicitly call when to allocate and free memory, we don’t need the use of a slow and taxing garbage collector to hurt performance. However, there are numerous issues that can arise from poor memory management implementations done by developers. Memory leaks, use after free, double free, just to name a few. This meant that for many years, developers had to choose from a language that had either slower code with managed memory allocation, or faster code with questionable security.
This is where Rust steps up to the challenge. Rust is a compiled language that does not ship with garbage collection, and also doesn’t have any of the traditional memory issues that arise from developer error because it doesn’t expose memory allocation to the developer. But how is that possible?
Rust introduces a new concept of “ownership,” the idea that sections of memory can only be “owned” by one variable at a time, and everyone else who wants to access its data must “borrow” it from the owner. On top of this: all variables, regardless of their location in memory, are freed upon exiting their local scope. These two concepts combine to allow for an extremely powerful and robust memory management system that doesn’t require garbage collection.
Let’s say we have the following snippet of code, taken from the official Rust book’s chapter on ownership:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}
In this case, we have a single String structure being initialized using its member function from, which allocates the memory for us. We then do something with that variable on the second line. What happens? Assuming C/C++ memory allocation logic here, s1 should contain a pointer to the string in the heap. Therefore, copying it to s2 should just give us two pointers to the string, right? Also, what happens when we exit the scope? Didn’t we say that variables get freed when they exit scope? Wouldn’t that lead to a double free?
Let’s back up to that second line. With the way that Rust is designed, what happens here is not a shallow copy, but rather a move. We can confirm this behavior by running the following code:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
// ^ error[E0382]: borrow of moved value: `s1`
}
Because data can only be “owned” by one variable at a time, the value of s1 is moved into s2, meaning s1 is now empty and s2 is the only variable that contains data. Therefore, at the end of this block when all the variables are freed, we don’t have a double free!
There are a couple notes to add onto this, which I’ll gloss over quickly:
- Making deep copies is still possible!
- Some structs that derive from
Clonewill have aclonemember function which allows for them to be deeply copied into a new variable. - For example:
let s2 = s1.clone();works as expected. - See Section 3.5 for more details on derivable Traits.
- Some structs that derive from
- Primitives break the "move by default" rule, as they have a defined size and are quick to copy.
- To be more specific, primitive copying works primarily because both
xandyare stack-based and implement theCopytrait. - For example: Running
let x = 1; let y = x;sets bothxandyseparately to 1. - Once again, see Section 3.5 for more details on Traits.
- To be more specific, primitive copying works primarily because both
2.2) Ownership with Nested Blocks/Functions
Now, what happens if we pass a variable into a function? How does ownership work there?
Take the following example:
fn new_owner(input: String) {
println!("{}", input);
}
fn main() {
let s1 = String::from("hello");
new_owner(s1);
}
In this case, s1 is passed in as a variable to new_owner, which prints it and returns. Once again, assuming C/C++ memory concepts for the sake of explaining, we’d assume a reference to s1 is passed in to the function, and s1 should still be valid afterwards. However, that is not the case in Rust. Changing main to the following reveals yet another move has occurred:
fn main() {
let s1 = String::from("hello");
new_owner(s1);
println!("{}", s1);
// ^ error[E0382]: borrow of moved value: `s1`
}
Any block of code in Rust has the ability to claim variables that it needs and automatically move them into its scope. Functions have this ability as well. Knowing this, here’s what happens:
- When the string is generated, heap memory is allocated for
s1and initialized. - When
s1is passed into the function, Rust moves the value ofs1intoinput. inputis used as expected, then exits scope at the end of the function, and is freed.- Now
s1is empty, and when it’s used again, the compiler panics.
We can solve this issue by redefining our code to utilize the reference operator &, which allows for functions to “borrow” variables’ values without moving them from their owner:
fn borrower(input: &String) {
println!("{}", input);
}
fn main() {
let s1 = String::from("hello");
borrower(&s1);
println!("{}", s1);
}
2.3) Passing in Mutable Values
One last thing before I close this section out: I know many old C/C++ devs are used to the age-old tradition of manipulating strings (or other more advanced structures) within child functions by passing in a reference as an argument to a function. I’m glad to report that you can perform similar behavior here:
fn borrower_edit(input: &mut String) {
input.push_str(", world!");
}
fn main() {
let mut s1 = String::from("hello");
borrower_edit(&mut s1);
println!("{}", s1);
}
In fact, this behavior is commonly seen while retrieving input from stdin, which looks like the following:
let mut s = String::new();
io::stdin().read_line(&mut s).unwrap()
Rust is pretty neat in that you don’t have to worry about prepending * or & to variables within code blocks to actually refer to the right data in memory like you would in C/C++. Rust handles all of that context for us, so long as our function declaration is correct. Therefore, using variables within our code is as simple as just referring to them by their name!
For more information on Rust’s ownership system, see the docs’ section on ownership.
3.) Traits and Polymorphism
3.1) Recap of Inheritance/Polymorphism
If you’ve ever taken a basic computer science class, survey says you’ve been introduced to the topic of object-oriented programming and inheritance. The idea of inheritance is essentially the implementation of the “is a” relationship. For example: A rectangle is a shape. A triangle is also a shape. Both share some common features, but other aspects of them may vary, such as how you calculate their areas.
We can represent this in code using inheritance. Take the following Python code for example:
class Shape:
def __init__(self):
self.width = 5
self.height = 5
def get_dims(self):
return f"{self.width}, {self.height}"
class Rectangle(Shape):
def get_area(self):
return self.height * self.width
class Triangle(Shape):
def get_area(self):
return (self.height * self.width) / 2
In our code, we define a common parent “Shape” class that contains the width and height of our shapes, as those are two dimensions that are constant across our shapes. However, the formula to calculate their areas is different, so we split the shape class into two child classes: Rectangle and Triangle. Each of the child classes inherit the member variables and functions of the parent (i.e. width, height, and get_dims) but implement get_area differently.
Many textbooks will represent the relationships of child to parent classes using a tree, which might look like the following:
One of the benefits to using this tree-like understanding of inheritance is that it allows you to use a special concept in computing called polymorphism. It allows strictly typed languages like C++, C#, or Java to house different classes of data in a single collection, so long as each of the members of the array share a common parent class.
For example: In my Fall 2021 C# class, we used this concept to create an application that was able to show appointments and to-do list tasks within a single list. Both Appointment and Task classes were children of the Item class, so we were able to use a single List<Item> to store our collection of both Appointments and Tasks.
Rust is technically an object-oriented language, and it is strictly typed. So how does it handle this concept?
3.2) Intro to Traits
Totally differently. Rust takes your understanding of inheritance trees and throws them straight to the bottom of the dumpster. Enter: Traits.
Traits are a totally different way of implementing polymorphism in code. It works by getting rid of trees and instead having related classes implement common “traits” that contain common functions. Structures can implement multiple traits as well, making traits pretty powerful. To understand, Let’s try implementing that example from my C# class again, but this time using Rust.
We start by defining our structures.
pub struct Task {
title: String,
is_done: bool
}
pub struct Appointment {
title: String,
start: u64,
}
Now, we need to define a common trait for them to implement. Let’s call it Summary and put our function declarations in it:
pub trait Summary {
fn summarize(&self) -> String;
}
This snippet declares that implementations of this trait must define a summarize function that returns a string, similar to an abstract class function declaration in many other languages.
Let’s define our implementations:
impl Summary for Task {
fn summarize(&self) -> String {
format!("{} (Done? {})", self.title, self.is_done)
}
}
impl Summary for Appointment {
fn summarize(&self) -> String {
format!("{} (Starts: {})", self.title, self.start)
}
}
Now, in our main code, we can create a vector that houses any class that implements our trait as follows:
fn main() {
let items: Vec<Box<dyn Summary>> = vec![
Box::new(Task {
title: String::from("Task"),
is_done: false
}),
Box::new(Appointment {
title: String::from("Appointment"),
start: 1652659200 // 5/16/22 00:00 GMT
})
];
for item in items {
println!("{}", item.summarize());
}
}
There are a couple of things of note in this snippet, which I’ll break down individually:
- We use the
dyn Summaryphrase to let the compiler know that our code is going to be using any struct that implements theSummarytrait. - Because of how memory allocation works, we cannot use
dyn Summaryas our generic directly, and have to wrap it in aBox<T>. - This is mainly because our structs may differ in size, and it’s impossible for the compiler to allocate a constant size for each item in our vector if that’s the case.
Box<T>moves our initialized data to the heap, and simply stores a reference to that data. It essentially acts as a constant-size “smart” pointer, so declaringBox<T>as our vector generic type is legal.- The
Box<T>will also free any memory it allocated upon being freed, so we don’t have to worry about memory management either. vec!is just a useful macro that allows us to generate a vector inline
Now, when we run it:
Task (Done? false)
Appointment (Starts: 1652659200)
3.3) Default Trait Implementations
If we were to want to have a default implementation of a function within a trait, we can do so by replacing the function declaration in our summary with an actual implementation of this function.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read More...)")
}
}
Then, if we were to define a new struct that uses this trait without overriding summarize, it would use the default definition in runtime:
struct Homework {
title: String,
class: String,
}
impl Summary for Homework {}
// Now, calling Homework::summarize()
// returns "(Read more...)"
3.4) Using Traits with Functions
Structs with Traits can also be used as parameters for functions as well. The function declaration looks a bit like defining a generic function, but we specify what traits we want our parameter to have using the : notation within the generic declaration:
fn some_function<T: Summary>(item: &T) {
println!("{}", item.summary());
}
(Optionally if you want a parameter to implement more than one trait, you can use the + notation to show that. For example: func<T: A + B>(item: &T))
You can also use Box<dyn Trait> as a return type, if you know that your function will return a struct with a trait, but are not quite sure which struct exactly:
fn which_struct_hehe(i: i64) -> Box<dyn Summary> {
if i % 2 == 0 {
Box::new(Task {
title: String::from("Task"),
is_done: false
})
} else {
Box::new(Homework {
title: String::from("Calculus Assignment #1"),
class: String::from("MAC 2311")
})
}
}
3.5) Common Derivable Traits
There are several Traits that the compiler is able to automatically implement for us, via usage of the special derive attribute.
Attributes are metadata declarations that can be applied to certain parts of code, such as modules, crates, or items. They typically take the form #[attribute] and go right before the code you want it to apply to. Think of them as a mashup of decorators from Python and preprocessor directives from C/C++. Here’s an example:
#[derive(Clone, Copy, Debug)]
struct Foo;
fn main() {
let x = Foo;
let _y = x; // prefixed to silence warning
println!("{:?}", x);
}
Earlier in the post I mentioned that stack-based primitives will be duplicated rather than moved by default. This isn’t due to any special treatment from the compiler because it’s a primitive, but rather because it’s a data type that implements the Copy trait. Our example above does as well. In fact, Foo derives from 3 traits:
- Clone is the trait that implements the deep copy methods to “clone” a variable. (i.e. the
clonemember function) - Copy is the trait that tells the compiler to use
Cloneand make a copy by default instead of the default move behavior. - Debug is an optional trait that allows for us to print out our structs using the
{:?}formatter inprintln!.
There are several other traits than can be implemented via derivation. See the docs for more info.
Now in this case, when we run let _y = x;, the compiler makes a clone of the data owned by x and places it in _y, essentially making two identical but separate variables in memory. This is why the following line, println!("{:?}", x); actually runs, while the examples in Section 2.1 which use String— a struct that doesn’t derive from Copy— will not work.
For more information on Traits, see the docs’ section on Traits.
4.) Error Handling
4.1) Traditional Try-Catch Blocks
C++, Python, and many popular languages nowadays have similar paradigms for handling runtime errors in code. They all use the try-catch architecture to implement their error handling, and it looks a bit like what follows:
try:
raise Exception("This is an error!")
except Exception:
print("Gracefully handling error...")
Typically, somewhere in your code, you’d raise an exception where something went wrong. This error would then propagate up the stack until it either A.) gets handled by a try-catch block somewhere above it or B.) climbs up the entire stack without being handled and causes the application to halt execution. Pretty simple right?
However, this implementation provides an issue. Exceptions traditionally all derive from a single parent Exception class. In Python, all exceptions must derive from Exception or another exception class that eventually derives from Exception. But we just determined that inheritance doesn’t exist in Rust, so how would this work?
4.2) Rust’s Result Type
Because of its differences from other languages, Rust doesn’t use a try-catch architecture for error handling, and instead uses its main Result class for everything.
The closest parallel I can draw to it is JavaScript’s Promise class, but even that’s a stretch. Essentially, instead of returning a value directly, any function that may fail returns a Result Enumeration, which could contain either the data you want or an error struct. Code that calls one of these functions must parse whether the result returned data or an error and handle it properly.
Let’s go through an example. Take the following code below:
use std::fs::File;
fn main() {
let f = File::open("hello.txt");
}
Because opening a file is an operation that could fail for multiple reasons, (file handle already open, file doesn’t exist, file isn’t readable, etc.) it shouldn’t return a File object directly and instead needs to return a Result, so we can properly handle it. This result contains either a File or an Error, and we can use Rust’s powerful match statement to filter it:
fn main() {
let f = match File::open("hello.txt") {
Ok(file) => file,
Err(error) => panic!("Something went wrong!"),
};
}
If the result is a success, then this code should put our file object in f for us to use. However, if the file fails to open, then we use the panic macro to halt execution immediately and say that something went wrong.
This is a bit clunky though, so most people end up using Result’s unwrap and expect functions instead. They both function similarly to the code above, either returning the success value or calling panic! for us, and the only difference is that expect allows us to be more specific by adding an extra string to the stack trace upon a panic. Here’s an example:
fn test_unwrap() {
let f = File::open("hello.txt").unwrap();
// ^ thread 'main' panicked at 'called `Result::unwrap()`
// on an `Err` value: Error {...}
}
fn test_expect() {
let f = File::open("hello.txt").expect("Failed to open file");
// ^ thread 'main' panicked at 'Failed to open file:
// Error {...}'
}
4.3) The “?” Operator
Sometimes you may find yourself in a position where you’re designing a function with error handling that may need to propagate an error up the stack without panicking. In that case, using unwrap or expect won’t work for us, and we need to return the error that was given to us by the error-prone function we called. We can do that by directly returning the error that we received from our function. Another example:
fn read_from_file() -> Result<String, io::Error> {
let mut f = match File::open("data.txt") {
Ok(file) => file,
Err(e) => return Err(e),
};
// --snip--
}
This function will either set f to contain our File instance, or return the error to the caller function. Neat right? But most certainly clunky. How can we streamline this?
Rust has a special operator called the ? operator, only for use in functions that return a Result, that acts as a shorthand for this. Here’s what our code would look like with the operator in use:
fn read_from_file() -> Result<String, io::Error> {
let mut f = File::open("data.txt")?;
// --snip--
}
As you can see, our code now exhibits the same behavior, but with the addition of a single character rather than 4 lines of code. If the file opens, the ? puts the value in f. If the open fails, ? returns the error value from our function immediately, allowing for it to propagate it up the proverbial chain of command.
For more on Rust’s Result type and how to use it, see the docs’ section on Result.
5.) Closures
5.1) What is a Closure?
If you’ve ever programmed in JavaScript before, you’ve almost assuredly seen one of these:
var temp = 100;
func_w_callback(function() {
console.log(temp);
})
func_w_callback is a function that takes in another function to be called back to later in code. Callbacks are used pretty frequently in JS because of how it’s designed, so this structure of passing in an anonymous function as an argument is pretty common. However, the reason this is useful in JS is because of a special behavior that all anonymous functions in JS have: they all act as closures.
What is a closure? Essentially, a closure is a special feature of functional programming languages that allow child functions to access data within the scope of its parent.
In our JavaScript example, the usage of a closure means that we can access data from the parent scope within the callback defined for func_w_callback. But why is this useful? Why not just define two separate functions? Let’s look at the following example in Python:
def wrapper(f):
return f()
def checker():
return temp == 100
def main():
temp = 100
print(wrapper(checker))
While this structure may seem common for Python devs who design decorators— fancy closures that allow you to modify the output of another function— most surface-level devs may not understand what’s going on here. So let’s break it down:
- We define a
mainfunction, which we’ll need to call manually later. This function sets the value oftemp. - We define a
wrapperfunction, which takes in a single functionf, executesf, and returnsf’s return value - We define a
checkerfunction, which simply checks to see if a variabletempis equal to 100.
In this case, our code will not run because temp is not defined within checker’s scope. However, if we make the simple change of moving checker’s definition inside of main’s definition, then it works!
def wrapper(f):
return f()
def main():
def checker():
return temp == 100
temp = 100
print(wrapper(checker))
Because temp is defined in the scope of main, and checker is defined within that same scope, checker acts as a closure and is allowed to reference the variables within its parent’s scope. Therefore, we can reference temp with no issue.
Circling back to our JavaScript example, we can now see why anonymous functions are favored so much. Using a closure allows for our anonymous callback function to use any of the data that was being processed before func_w_callback was called! Neat!
So how are closures used in Rust?
5.2) Closures in Rust
Closures in Rust can be used in many ways, but you’ll primarily see two main uses:
- Defining “lambda” functions
- Writing threads for multiprocessing
Closures in Rust can be used to define quick and dirty “lambda” functions to use in code, like as follows:
let func = |i: i32| -> i32 { i + 1 };
This defines an anonymous function that takes in a single parameter, i, and returns that value plus one. This function is then assigned to the func variable. However, closures can generally infer types pretty easily, so we can shorten our code to as follows:
let func = |i| i + 1;
Pretty simple and fluid right? Let’s see how we can use closures to make multithreading pretty simple.
5.3) Basic Multithreading in Rust
As stated earlier, closures are used pretty frequently in multithreading in Rust. The thread::spawn method from the standard library takes in a single function to run throughout its lifetime. In many cases, developers will prefer to pass in closures instead, to allow their child threads to access information from the parent thread.
Let’s look at the following example:
use std::thread;
fn main() {
thread::spawn(|| {
println!("Hello from the child thread!");
})
}
This code spawns a single child thread that is fairly standalone. It doesn’t access any information from the parent scope, and simply prints a line to stdout whenever it’s executed by the OS’s scheduler. Multithreading gets a bit more complex when we deal with using data from parent scope, however. Take a look at the following example:
use std::thread;
fn main() {
let x: i64 = 100;
thread::spawn(|| {
println!("{}", x);
})
drop(x);
}
There is a large issue in this code. Because closures are like any other block of code, we’d expect the value of x to be moved into the closure, just like we established in section 2.2 right?
Incorrect. Closures borrow values by default, instead of moving them. Because of this, our code runs into a major race condition. x may be dropped before it is able to be used in our thread, depending on how our OS’s scheduler decides to prioritize our threads. This is unsafe behavior, and to make our code safe, we need to either move the original value or make copies of the data we need in our threads.
Luckily we can force closures to do the expected move behavior by prepending move to our closure declaration.
use std::thread;
fn main() {
let x: i64 = 100;
thread::spawn(move || { // <-- x is moved here
println!("{}", x);
}) // <-- x is dropped here, after being used
// <-- at this point, x no longer exists
}
Now the thread takes ownership of the x variable, and we don’t have to worry about it being dropped before it’s used.
In the case that you’re using multiple threads, you can combine move closures with clone and variable shadowing to make spawning multiple independent threads easier.
use std::thread;
fn main() {
let s = String::from("Hi from thread");
for i in 1..=10 {
let s = s.clone();
let t = thread::spawn(move || {
println!("{} {}", s, i);
});
}
}
For more information on using threads in Rust, see the docs.
Summary
Rust is most certainly a new take on systems programming that introduces a radically different way of designing your programs. Its ownership concept makes memory management very secure, without sacrificing the speed that comes from garbage collected languages. Rust’s Trait concept also provides a new way of thinking about your structures allowing for structures to share behavior with any other structure, regardless of inheritance. Error handling is handled in a new robust way and closures allow for easy implementation of anonymous functions for use in threads or quick solutions.
This post only goes into the basics, and the only way from here is up. I highly suggest that you read the official book from the Rust maintainers, which can be found online for free here or hardcover from No Starch Press. If you’re more into examples rather than reading long-winded explanations, then Rust by Example might be more up your alley. Both the textbook and RBE explain everything stated here in a much more detailed manner, and I highly recommend perusing through them if you’re interested in learning more.
For now, this is all that I have. I hope you enjoyed the read, and I’ll see you in the next post!